Multi stage setup with Terraform

Today we are going to extract a Terraform module from our setup, in order to have multiple stages, like development, staging and production.
In the past articles of this series I’ve described a simple setup of a web-app on AWS. I included AWS Lambda for some backend functionality, S3 to store static website files, CloudFront as a caching router, and Hetzner cloud DNS to publish the service under a domain. For a hobby project, this is enough, but when we develop software professionally, we usually have multiple stages of the complete system running in parallel.
At the very least, we have two stages:
- “production” (short “prod”) is the system used by the actual users.
- “staging” contains different instances of the same component. The same code, the same database schema, but generally different data (i.e., test-data). This stage exists so that we can test and possibly break things without affecting the actual users of the system. Often, we run a set of end-to-end tests against staging, which test the system before everything gets deployed to production.
- I worked on a project where “staging” was used by dedicated testers to click through test-plans. To stop developers from interfering with testers, we deployed another “development” stage (short “dev”) as a developer testing-ground.
- In another project, we were using “review” environments. We were using GitLab and Merge Requests (MR) in our workflow; the CI/CD pipeline would deploy a dedicated clone of the application for every MR.
So far, my “placeruler” app just has a single stage: Production
Let’s change that.
Terraform modules
Terraform modules are a way to reuse Terraform code in different places, and to an end, deploying multiple stages just means reusing the code of the whole application multiple times. So our goal here is to extract a module that deploys the whole application, which we can then use with different parameters.
How do modules work in Terraform?
We can create a directory with some Terraform files in your project and call
that module with a module declaration in the main project.
- Inputs: If we want to pass data into the module, we can use a
variable-statement inside the module. - Outputs: If we want to return data from the module, we can use an
output-statement.
Note that we’ve used both statements before in previous blog posts. We used
variables to pass in an access token via a hetzner.auto.tfvar file, which we
didn’t want to add to git.
We used output to show the actual function URL of a deployed Lambda because we
wanted to test this part without applying DNS changes. We also used and output
for the bucket name of the website files, so that read it from the script that
actually copied the files to the bucket.
A module is simply a directory with terraform configurations. We can pass in variables and retrieve outputs. For example, consider this file structure:
├── main.tf
└── trivial-module
└── main.tfThe file trivial-module defines a variable and return a that variable with a
prefix.
variable "some-variable" {
type = string
}
output "some-return-value" {
value = "The return of ${var.some-variable}"
}The root module (i.e., /main.tf) calls this module, passes in the variable,
and outputs the return value (which will print it to the console)
module "trivial-module" {
source = "./trivial-module"
some-variable = "the king"
}
output "module-return-value" {
value = module.trivial-module.some-return-value
}Running terraform apply in the root directory, will output “The return of the
king” to the console.
So, to create a module from our app, we just move it to a directory?
Basically, yes. But we should follow some best practices. So far, we had the following file structure
.
├── certificate.tf
├── cloudfront.tf
├── hetzner-dns.tf
├── lambda.tf
├── providers.tf
└── s3-website-files.tfThe variables and outputs are distributed across these files, which makes it
difficult to find them all.
The Terraform documentation provides this basic structure of a module
.
├── LICENSE
├── README.md
├── main.tf
├── variables.tf
├── outputs.tfThe modules in
terraform-aws-modules
also have a versions.tf file containing required provider versions.
I would not put all Terraform code into a single main.tf, but having a
separate variables.tf, outputs.tf and versions.tf certainly makes sense.
It makes sense to split the code into more modules, but not for this post.
Basic structure of the multi-stage setup
So far, we’re using this structure:
.
├── modules
│ └── lambda-with-website
│ ├── certificate.tf
│ ├── cloudfront.tf
│ ├── hetzner-dns.tf
│ ├── lambda.tf
│ ├── outputs.tf
│ ├── s3-website-files.tf
│ ├── variables.tf
│ └── versions.tf
├── README.md
└── stages
└── prod
├── hetzner.auto.tfvars
├── main.tf
├── providers.tf
└── variables.tfIn the file stages/prod/main.tf we call the module
modules/lambda-with-website. Let’s consider some more aspects of this
migration:
Variables and Outputs
Which inputs and outputs do we actually need? Which resources actually differ from stage to stage?
- Variable
domain_name: We certainly want to deploy “staging” on a different domain than “production.” - Variable
dns_zone: Maybe we don’t want to deploy staging to a subdomain of “knappi.org” at all. - Variable
name_prefix: If we use a different AWS Account for all stages, we don’t need this input. But in the projects that I worked in, we usually had only two accounts, one for production and one for non-production deployments. That means we have all resources for staging, dev, and review environments in one account. To prevent duplicate resource-names, we need to add some kind of prefix, likestaging-, ordev-. - Output
s3_bucket_name: We still need to copy our files to the created bucket. If we want to have the source of truth in our Terraform code, we need to have this as an output. However, there are cases where you might want to use a naming convention instead; for example, if the frontend code lives in a different repository. In that case, we don’t need this output.
Providers
The Terraform documentation states that a reusable module shouldn’t have
provider definitions. Instead, we’re only allowed to specify the
terraform.required_providers configuration.
The aws.us_east_1 provider alias is a bit tricky here, because it requires
special configuration. For reusable modules, this is done via the
configuration_aliases property:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
configuration_aliases = [aws.us_east_1]
}
archive = {
source = "hashicorp/archive"
version = "~> 2.0"
}
hetznerdns = {
source = "timohirt/hetznerdns"
version = "2.1.0"
}
}
required_version = ">= 0.13"
}In my current version of the “Terraform and HCL” plugin (243.23654.44), the
configuration_classes property was not supported. This is a bit frustrating
because I get no autocompletion and the aws.us_east_1 line is always shown as
error. I hope this will get better soon.
In our root module, we need to define the correct providers. The aws.us_east_1
provider must be passed in explicitly, because it is a provider with an alias.
In stages/prod/providers.tf:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
archive = {
source = "hashicorp/archive"
version = "~> 2.0"
}
hetznerdns = {
source = "timohirt/hetznerdns"
version = "2.1.0"
}
}
required_version = ">= 0.13"
}
# Configure the AWS Provider
provider "aws" {
region = "eu-west-1"
}
# Configure the AWS Provider
provider "aws" {
alias = "us_east_1"
region = "us-east-1"
}
# Configure the Hetzner DNS Provider
provider "hetznerdns" {
apitoken = var.hetzner_dns_token
}In stages/prod/providers.tf:
module "lambda-with-website" {
source = "../../modules/lambda-with-website"
dns_zone = "knappi.org"
domain_name = "lambda-example.knappi.org"
name_prefix = ""
providers = {
aws.us_east_1 = aws.us_east_1
}
}Migrations
So, we’ve extracted our module, we copied the Terraform state to stages/prod
and now we run terraform apply -auto-approve…
… and see with tears in our eyes that
- resources like the Lambda and Cloudfront have been removed,
- the deployment was canceled midway because the S3 bucket couldn’t be deleted. It still contained some files.
But why should it be removed in the first place? We didn’t want to create new AWS resources. We just wanted to refactor our Terraform definitions.
To Terraform, the resource for the S3 bucket is called
aws_s3_bucket.static-website it is stored in the tfstate under that name.
Moving the definition to the module changed that name. It is now called
module.lambda-with-website.aws_s3_bucket.static-website.
Since Terraform doesn’t know of our refactoring, it has to assume that the prior resource has to go and the new one has to be created.
In our example app, this is no problem. No one is using it anyway, and we don’t have any relevant data that is not also part of our repository. But for the common application with user data and uploaded files, we need to have a way to keep our resources intact.
Moved
Let’s pretend we didn’t apply those changes but rather had a look at the plan first. We could have solved the problem by using a moved statement:
moved {
from = aws_s3_bucket.static-website
to = module.lambda-with-website.aws_s3_bucket.static-website
}This tells Terraform that we moved the S3 bucket to the module. It can keep the resource instead of re-creating it.
I’m not an expert in Terraform. I’m just learning it. But I have a lot of general experience in software development. The following statement may not be true, but I think it is highly likely.
If we want to ensure a zero-downtime deployment for this migration, I would assume that we need to do more than keep the S3 bucket. We need to make sure CloudFront is not deleted, and it would also be a good idea to keep the Lambda around.
It tried to apply moved statements manually and running terraform plan over
and over again. It was slow and frustrating. Then I ran:
bin/plan.sh prod | grep destroyedand did some regex-replace magic, replacing
# (\S+) will be destroyedwith
moved {
from = $1
to = module.lambda-with-website.$1
}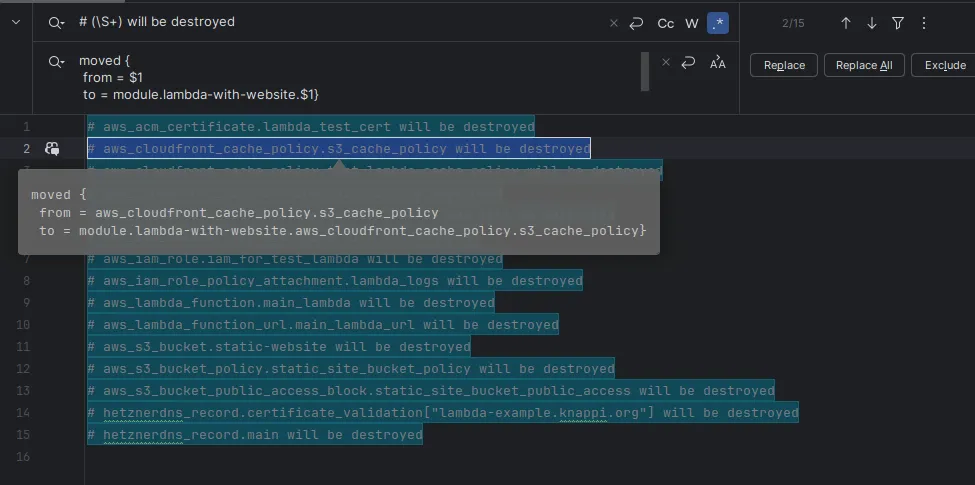
and saving everything as migration-001.tf.
I’m sure this would have worked if I had not done other changes as well, such as fixing the name of the Lambda. In the end, I’m not sure if the deployment was without downtime or not. But I’m sure of my conclusion.
Conclusion
Extracting the whole application as a module is a viable way to do multi-stage deployments. It is cumbersome to do this while the system is already running, without causing downtime.
If the S3 bucket is called website-static it can’t be renamed to
prod-website-static easily.
It would have been much easier to start with a single application module, a single stage, and correct names from the beginning.
The current state of the example project can be found in branch 0035-multi-stage-setup. If you want to try the migration yourself:
- Checkout
0034-cloudfront-s3-multi-origin. - Setup accounts and access tokens as described in the previous articles ( setup
hetzner.auto.tfvarsand your AWS account). - Run
bin/deploy.shto deploy everything. - Checkout
0035-multi-stage-setup, copyterraform.tfstateandhetzner.auto.tfvarstostages/prod. - Remove
stages/prod/migration-001-move-to-module.tf. - Run
bin/plan.sh prodand look at the plan. Everything is removed and created anew. - Recreate
stages/prod/migration-001-move-to-module.tffrom the git history. - Run
bin/plan.sh prodand look at the plan again. Some things are replaced, but most of them are retained. - Run
bin/deploy.sh prodto deploy everything.
My other conclusion is that Terraform is great and I really like it. I can extract functions (i.e., modules) and keep my code clean that way. That’s all I need…