I wrote my own lexer

"Small" does not have to mean "dirty". For my "handlebars-ng" project, I rewrote an existing JavaScript lexer from scratch and despite my focus on readable code and a concise architecture, it turned out to be smaller than the original and slightly faster.
For my handlebars-ng-project, I was looking for a lexer, and I found the moo-lexer. The simplicity of configuration and the fact that it has zero dependencies convinced me to use it.
Creating a tokenizer is really simple:
const lexer = moo.compile({ ALPHA: /[A-Za-z]/, DIGIT: /\d/, COLON: ":" });
lexer.reset("ab1:2");
const tokens = [...lexer];
/*
tokens = [
'{"type":"ALPHA", "value":"a", "text":"a", "offset":0, "lineBreaks":0, "line":1, "col":1}',
'{"type":"ALPHA", "value":"b", "text":"b", "offset":1, "lineBreaks":0, "line":1, "col":2}',
'{"type":"DIGIT", "value":"1", "text":"1", "offset":2, "lineBreaks":0, "line":1, "col":3}',
'{"type":"COLON", "value":":", "text":":", "offset":3, "lineBreaks":0, "line":1, "col":4}',
'{"type":"DIGIT", "value":"2", "text":"2", "offset":4, "lineBreaks":0, "line":1, "col":5}'
]
*/You can have more complicated rules as well, and multiple states.
const lexer = moo.states({
main: {
OPEN: { match: "(", push: "footnote" },
CONTENT: { fallback: true },
},
footnote: {
CLOSE: { match: ")", pop: 1 },
DIGIT: /\d/,
},
});
lexer.reset(
"There are 4 sides of the history (1): My side, your side, the truth and what really happened. (2)",
);
const tokens = [...lexer];Only the rules of the current state apply and the fallback-rule matches
everything between matches of other rules. In the above example, the 4 is not
recognized as DIGIT, because it is not enclosed by brackets.
All this I could use well for my Handlebars rewrite, so I started using moo
and I was happy…
… until I got to the point where I needed something that moo didn’t offer
Look-ahead
Some tokenizer rules of the original Handlebars project have a look-ahead parameter. For example
const rule = { regex: /ab/, lookahead: /c/ };means that rule should match ab but only if it is followed by c and c
should not be part of the match. There is no lookahead option in moo.
Spoiler: moo does not need to have a look-ahead option, because you can
use
assertion syntax
in Regular Expressions. ab(?=c) would have solved my problem and I would never
have stepped into the following venture. But I found out about that only when I
tried to implement lookahead in own lexer.
So what I did was look at moo’s code and I didn’t like it too much…
One big file
At the time of this writing, the moo-lexer consists of a single JavaScript file which is 642 lines long. It starts with utility functions, followed by functions that compile the config into a lexer, then followed by [the Lexer class]in line 399 itself.
It contains some very large functions: The compileRule-function is 110 lines long.
The _token-function is not as long as “compileRule”, but it does a variety of things.
Having seen a lot of talks about Clean Code, SOLID principles and code
architecture lately, I thought: “Maybe I should just try and write my own moo,
use it to practice test-driven development, and see if I can apply all these
principles?” More importantly I wanted to find out how the focus on clean and
readable code would affect performance and bundle size.
On difference between my goals and moo certainly was that I didn’t have to
care about legacy browsers. I wanted to use the tooling that I usually use:
TypeScript, vite and vitest…
I also didn’t implement everything that moo is able to do, so the size comparison may a bit flawed.
How does moo work?
Let’s start with the simple configuration:
moo.compile({ ALPHA: /[A-Za-z]/, DIGIT: /\d/, COLON: ":", COMA: "," });Regex matching
What moo will do here essentially, is to combine all rules into one large
regex similar to
const regex = /([A-Za-z])|(\d)|(:)|(,)/y;The y flag makes sure that regex.exec() does not match anywhere after, but
only exactly at regex.lastIndex.
It then inspects the capturing groups of the result to find out which of the rules actually matched.
If the regex matches for example a 0, the result of regex.exec() is
["0", null, "0", null, null].
- Whole match:
0 - First group
([A-Za-z]): null - Second group
(\d):0
Ah, so the match was due to the DIGIT rule.
Fallback rules
If a fallback rule is applied, the regex gets the g flag instead of y, which
will then look for matches further ahead in the string. If there is a “gap”
between the last and the current match, a fallback token will be created and the
current match will be stored as queued and then returned in the next next
call.
Fast matching
There is a different matching strategy for matching tokens: The rules for
COLON and COMA just consist of a single char and there is no fallback rule
in our configuration, so ´moo` can use a much simpler and faster algorithm
before running the regex:
During compile time, it creates an array where each rule is stored at the index of its strings char-code
const fastLookup = [];
fastLookup[":".charCodeAt(0)] = colonRule;
fastLookup[",".charCodeAt(0)] = comaRule;In order to find the rule matching the current char, we just need to look into the array:
const matchingRule = fastLookup[string.charCodeAt(offset)];This resolves all single-char rules with a single array-lookup and is very fast.
Position tracking
When each match, moo inspects the matched string, counts linebreaks and the
size of the last line. This allows it to keep track of the current position. The
linebreak count and the current offset become part of the token.
At this point, I should mention that moo’s token format was not exactly what I needed. I needed “start” and “end” position of a token, not the number of line-breaks. I decided for my lexer to return my required token format instead of moo’s.
My own lexer
Since moo obviously comes from the cow, I decided to sheepishly name my lexer
baa-lexer. I actually wrote the lexer three times
as an exercise. Internally, it now works with the following data structures:
BaaTokenis my token format. It contains{ type, original, value, start, end }, wherestartandendboth containlineandcolumn. It resembles format used by Handlebars.- We include the token type in the
Ruleobject, so that at “runtime” the code only has to deal with rules of the form{ tokenType, match?, push?, pop?, next?, value? }and not with its short forms. - In addition to the “token” itself, we introduce a lightweight
Matchobject, which contains the fields:{ rule, text, offset }. That way, we can separate the code that finds aMatchfrom the code that actually creates the token and performs the location tracking.
The core of baa consists of interfaces for various components:
Matcherhas amatchmethod that returns a match in a given string at a given offset. just theoffsetwithin the string, the matching rule and the text. The default implementation is a composition of theRegexMatcherand theStickySingleCharMatcher, which implement the two matching strategies described above.StateProcessorprocesses matches in a givenState. There is a default implementation that uses aMatcherto find the next match. Between last and currentMatchit creates a fallback match if necessary, queuing the current match as “pending”.TokenFactorykeeps track of the current location (line, column) and has a method to create a token from a match. There is a default implementation for that as well, and it createsBaaTokens.Lexerhas alex(string)function that returns aIterableIterator<BaaToken>. The default implementation uses aTokenfactoryandStateProcessorinstances to tokenize the text. Its main responsibility is to keep track of state changes and call the correctStateProcessor.- The
baafunctions creates all necessary instances of those classes and connects them.
Notice how I always write: “There is a default implementation”. In theory, there can be custom implementations of each of those modules. You want to use a custom for finding matches? Write your own matcher. You want to process a state differently? Write your own state processor.
It is not possible yet inject a custom TokenFactory, but this is due to the
fact that the TypeScript typings become a lot more complicated by this, and that
I just don’t need this feature. But it can be done without affecting e.g. the
matching algorithm.
My source code now consists of about 12 files, each having their own responsibility. In my opinion easy to understand and to change.
Bundle size and benchmarks
You might ask: So many classes, what about the bundle size? What about performance?
Since I didn’t implement all of moo’s features, the bundle-size question may
be a bit unfair. moo claims to be “4KB minified + gzipped”. baa now has
about 2.2KB… I don’t think that implementing the remaining features would use
another 1.8KB, so I think this is fine.
Performance measures also show that my implementation is slightly faster than
moo, but this is also no conclusive test.
BENCH Summary
moo - performance/moo-baa.bench.ts > moo-baa test: './tests/abab.ts' (+0)
1.07x faster than baa
baa - performance/moo-baa.bench.ts > moo-baa test: './tests/fallback.ts' (+0)
1.19x faster than moo
baa - performance/moo-baa.bench.ts > moo-baa test: './tests/handlears-ng.ts' (+0)
1.50x faster than moo
baa - performance/moo-baa.bench.ts > moo-baa test: './tests/handlears-ng.ts' (1)
1.25x faster than moo
baa - performance/moo-baa.bench.ts > moo-baa test: './tests/handlears-ng.ts' (2)
1.19x faster than moo
baa - performance/moo-baa.bench.ts > moo-baa test: './tests/json-regex.ts' (+0)
1.15x faster than moo
moo - performance/moo-baa.bench.ts > moo-baa test: './tests/json.ts' (+0)
1.04x faster than baaTypescript typing
What I really like is getting support from the TypeScript compiler. This may not
be perfect yet, but with the baa-lexer, typings, you actually get
auto-completion and validation for token-types and state-names in many places.
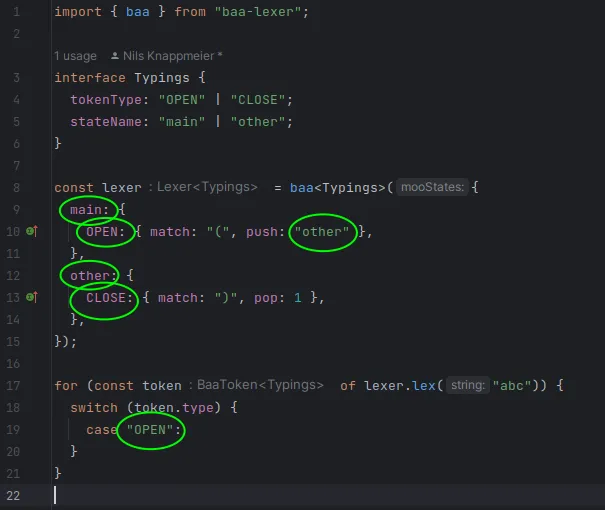
The good thing is that typings don’t add to the bundle size for browsers.
Conclusion

I have watched a lot of videos lately, about SOLID principles, clean
architecture and design and TDD. I tried to apply those principles when
implementing baa-lexer and I think that went quite well.
In the next posts I will talk a bit about what exactly I did to improve performance and reduce the bundle size of the project.